Users can deploy ready-to-use Kubernetes clusters with persistent storage for managing containerised applications. Only users that have access to the corresponding Project can perform operations with Kubernetes clusters.
To create a Kubernetes cluster
1. Go to the Kubernetes clusters screen, and then click Create on the right. A window will open where you can set your cluster parameters.
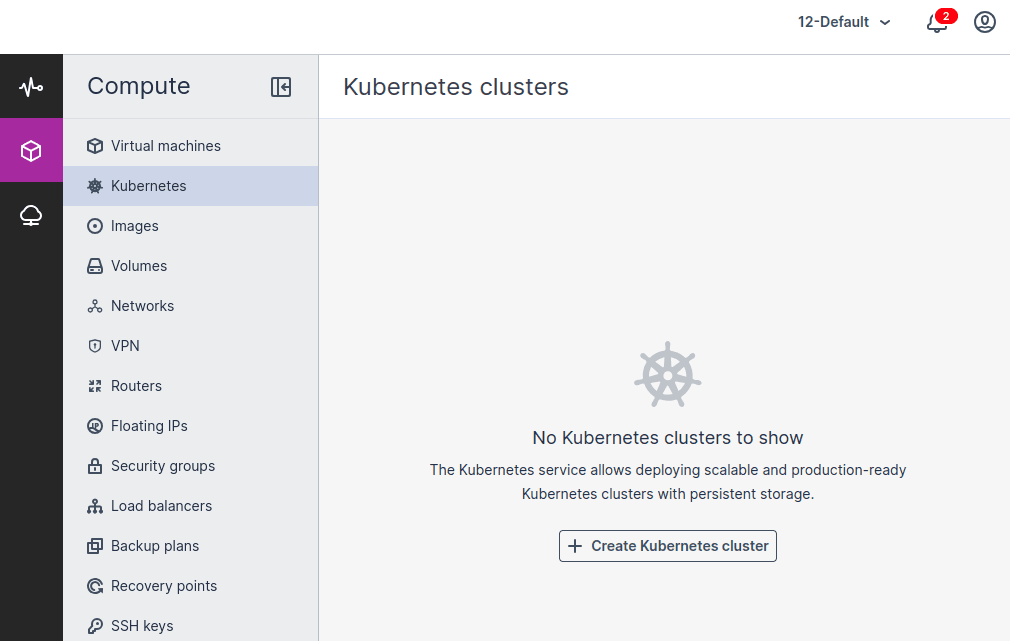
2. Enter the cluster name, and then select a Kubernetes version and an SSH key.
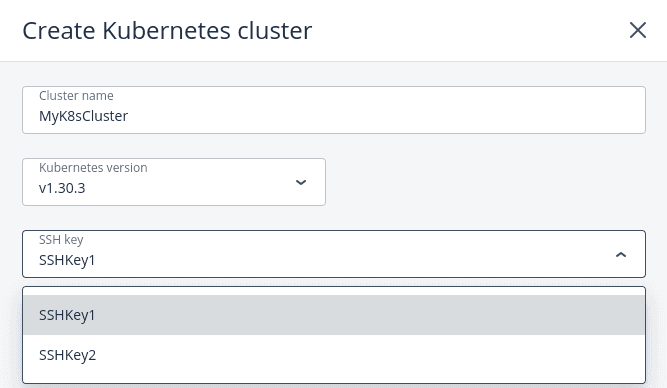
3. In the Network section, select a network that will interconnect the Kubernetes nodes in the cluster. If you select a virtual network, decide whether you need access to your Kubernetes cluster via a floating IP address.
- If you select None, you will not have access to the Kubernetes API.
- If you select For Kubernetes API, a floating IP address will be assigned to the master node or to the load balancer if the master node is highly available.
- If you select For Kubernetes API and nodes, floating IP addresses will be additionally assigned to all of the Kubernetes nodes (masters and workers).
Then, choose whether or not to enable High availability for the master node. If you enable high availability, three master node instances will be created. They will work in the Active/Active mode.
4. In the Master node section, select a flavor for the master node. For production clusters, it is strongly recommended to use a flavor with at least 2 vCPUs and 8 GiB of RAM.

Optionally, enable Integrated monitoring to automatically deploy the cluster-wide monitoring solution, which includes the following components: Prometheus, Alertmanager, and Grafana.
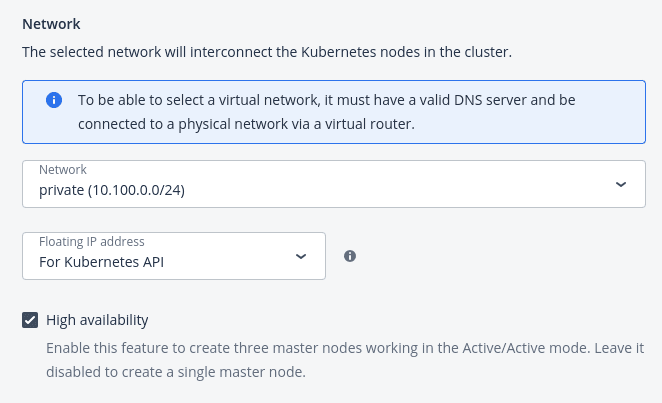
5. In the Container volume section, select a storage policy, and then enter the size for volumes on both master and worker nodes.
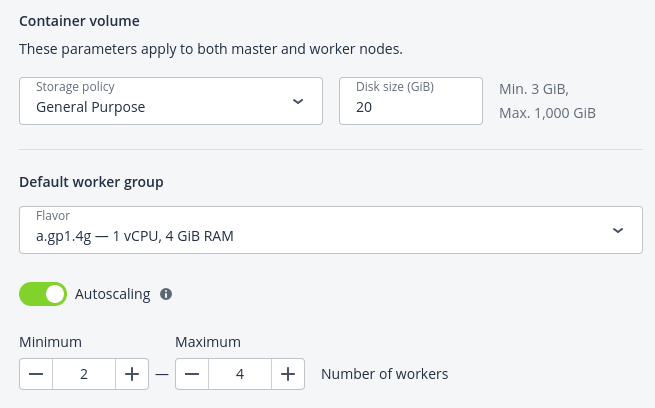
6. In the Default worker group section, select a flavor for each worker, and then decide whether you want to allow automatic scaling of the worker group:
- With Autoscaling enabled, the number of workers will be automatically increased if there are pods stuck in the pending state due to insufficient resources, and reduced if there are workers with no pods running on them. For scaling of the worker group, set its minimum and maximum size.
- With Autoscaling disabled, the number of worker nodes that you set will be permanent.
7. In the Labels section, enter labels that will be used to specify supplementary parameters for this Kubernetes cluster in the key=value format.
For example: selinux_mode=permissive.
Currently, only the selinux and flannel_network_cidr labels are supported.

8. Click Create. Creation of the Kubernetes cluster will start.
The master and worker nodes will appear on the Virtual machines screen, while their volumes will show up on the Volumes screen.
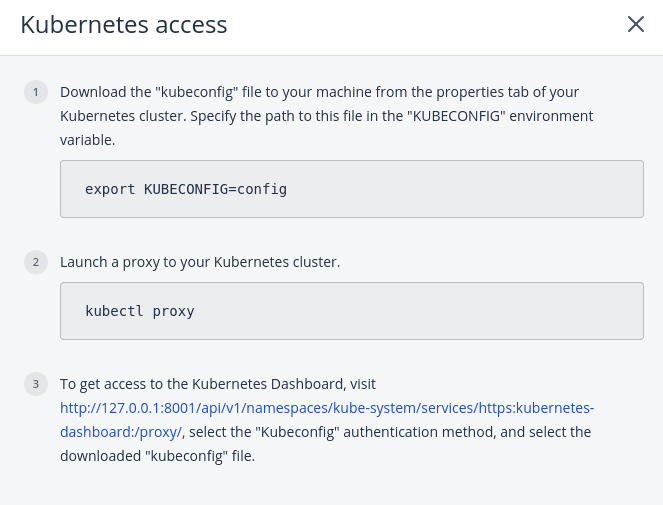
After the cluster is ready, click Kubernetes access for instructions on how you can access the dashboard. You can also access the Kubernetes master and worker nodes via SSH, by using the assigned SSH key and the user name core.
Accessing Your VM via SSH
To access your VM, use the following command from your local terminal:
ssh -i <private-key> core@<IP-address>
- Replace
<private-key>with the path to your private key file. - Replace
<IP-address>with the public IP of your VM.
🔎 For port accessibility, please verify from your network/firewall end if required.
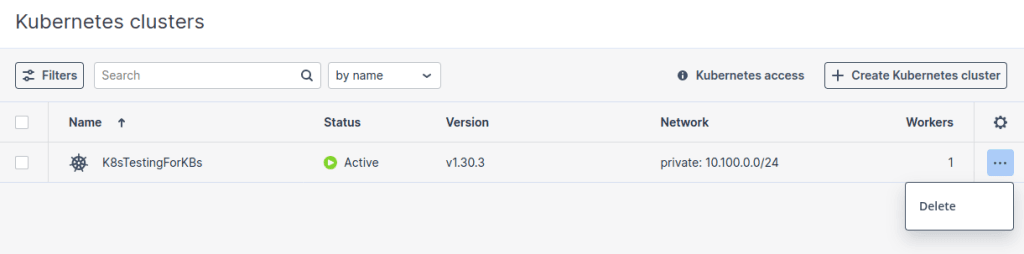
To delete a Kubernetes cluster
Click the required Kubernetes cluster on the Kubernetes clusters screen and click Delete, The master and worker VMs will be deleted along with their volumes.
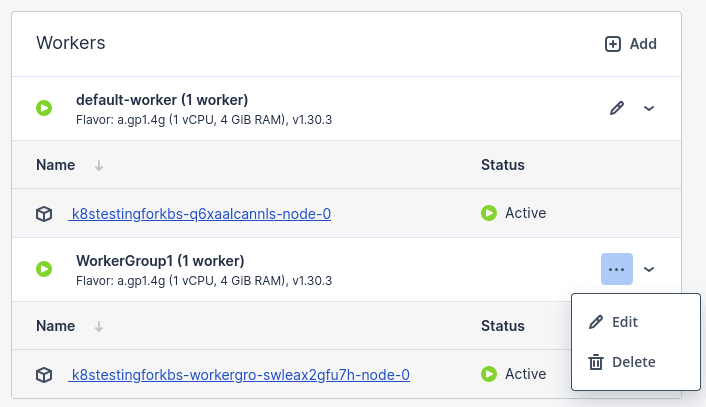
Managing Kubernetes worker groups
To meet the needs of your applications in Kubernetes, you can use worker nodes with different CPU and RAM configurations. This is done by creating worker groups with different setups.
When you first create a Kubernetes cluster, you can only configure one worker group, called the default worker group. After the cluster is set up, you can add more worker groups as needed and adjust the number of workers in each group later.
You cannot delete the default worker group.
To add a worker group
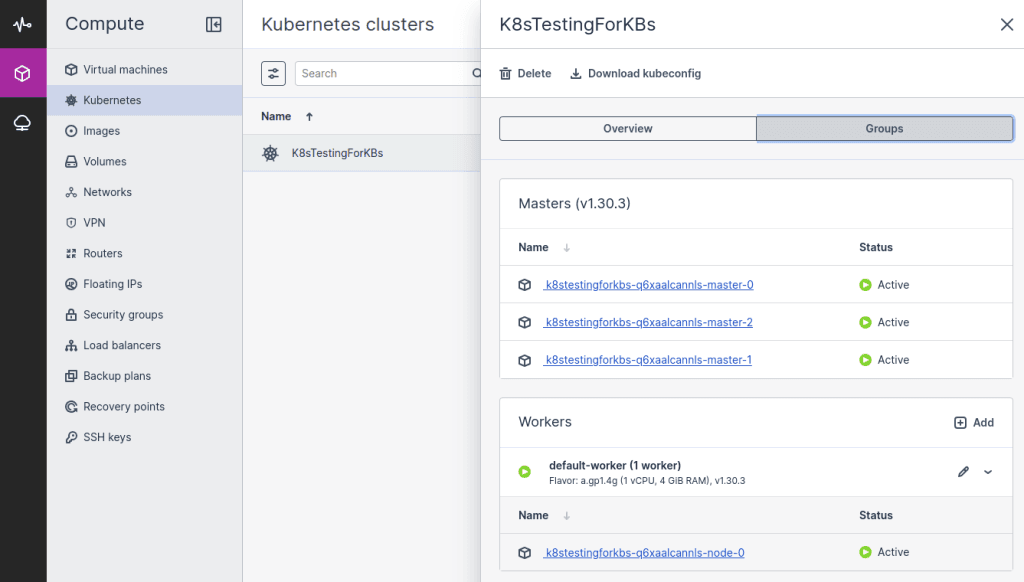
- On the Kubernetes clusters screen, click a Kubernetes cluster.
- On the cluster right pane, navigate to the Groups tab.
- In the Workers section, click Add.
- In the Add worker group window, specify a name for the group.
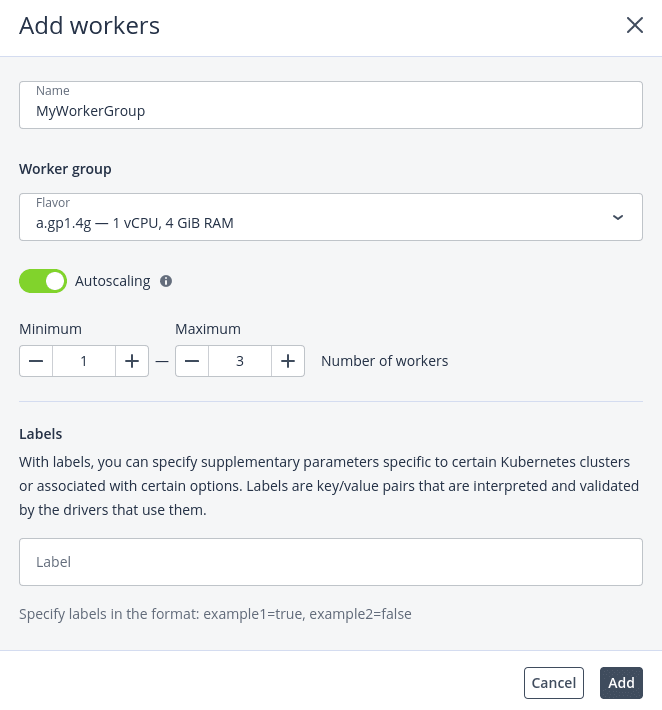
- In the Worker group section, select a flavor for each worker, and then decide whether you want to allow automatic scaling of the worker group:
- With Autoscaling enabled, the number of workers will be automatically increased if there are pods stuck in the pending state due to insufficient resources, and reduced if there are workers with no pods running on them. For scaling of the worker group, set its minimum and maximum size.
- With Autoscaling disabled, the number of worker nodes that you set will be permanent.
- In the Labels section, enter labels that will be used to specify supplementary parameters for this Kubernetes cluster in the key=value format. For example: selinux_mode=permissive. Currently, only the selinux and flannel_network_cidr labels are supported. You can use other labels at your own risk. To see the full list of supported labels, refer to the OpenStack documentation.
- Click Add.
When the worker group is created, you can assign pods to these worker nodes, as explained in Assigning Kubernetes pods to specific nodes.
To edit the number of workers in a group
- On the Kubernetes cluster right pane, navigate to the Groups tab.
- In the Workers section, click the pencil icon for the default worker group or the ellipsis icon for all other groups, and then select Edit.
- In the Edit workers window, enable or disable Autoscaling, or change the number of workers in the group.
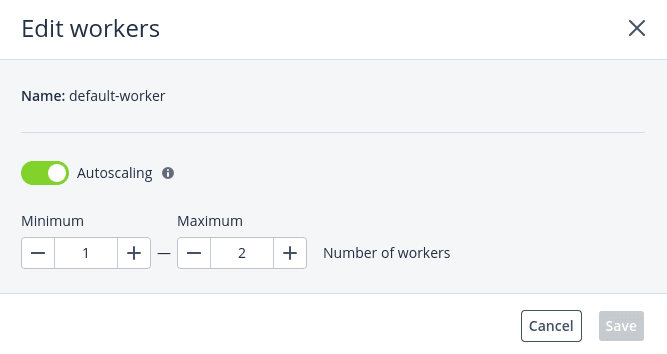
- Click Save.
To delete a worker group
Click the ellipsis icon next to the required worker group, and then select Delete. The worker group will be deleted along with all of its workers. After the deletion, the worker group data will be lost.
Updating Kubernetes clusters
When a new Kubernetes version is available, you can update your cluster. Worker nodes are updated one by one, with the data availability unaffected. The Kubernetes API will be down during the update unless the master node has high availability enabled.
You need to make sure that the compute cluster has enough resources and quotas for at least one extra VM of the largest flavor used by your Kubernetes cluster. If the master and worker node flavors differ, then you should take into account the largest one of them.
Limitations:
- Clusters with versions 1.15.x to 1.17.x cannot be updated to newer versions.
- Updates can only be done one minor version at a time (e.g., from 1.28 to 1.29, then to 1.30).
- Node groups can only have a one-minor-version difference (e.g., 1.29 and 1.30).
- Clusters using version 1.29 can be updated to 1.30 only if they were created with the Cilium network plugin.
- You cannot manage clusters in the self-service panel during an update.
To update a Kubernetes cluster
- Click a Kubernetes cluster that is marked with the Update available tag.
- On the Kubernetes cluster pane, click Update in the Kubernetes version field.
- In the Update window, do the following:
- Select a Kubernetes version to update to and follow the provided link to read about API resources that are deprecated or obsoleted in the selected version. Then, click Next.
- Choose how to proceed:
- Select Update all to update all of the node groups in the Kubernetes cluster.
- Select Custom update to update only specific node groups. The master node group is selected automatically and is mandatory for an update.
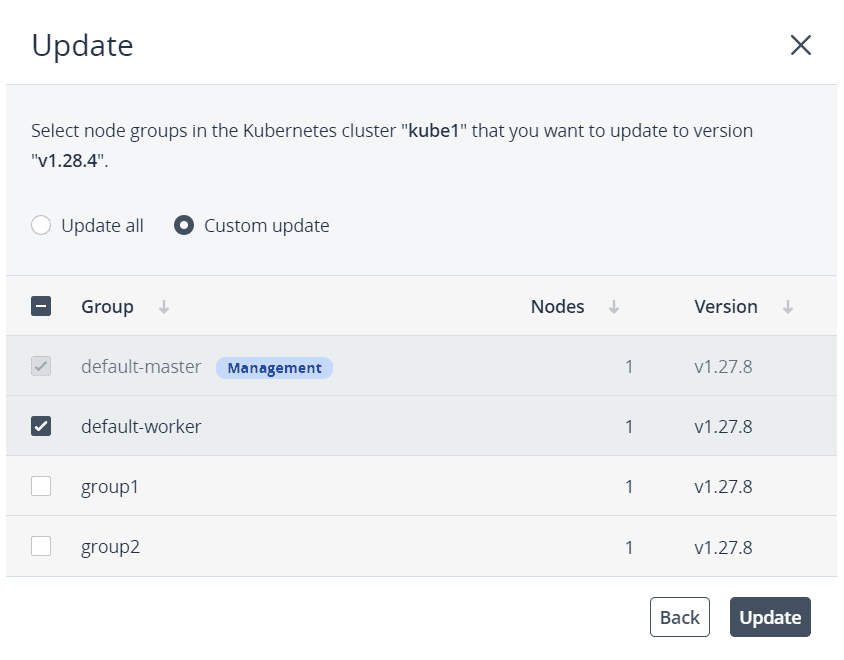
- In the confirmation window, click Confirm. The update process will start.
When node groups in a Kubernetes cluster have different versions, the cluster tag changes to Partially updated. In this case, new worker groups will be created with the version of the master node group. To finish the Kubernetes cluster upgrade, you need to repeat the update procedure for worker groups with an older version.